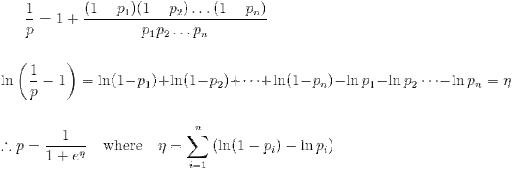Hi Guys,
For one of my course project I started implementing "Naive Bayesian classifier" in C. My project is to implement a document classifier application (especially Spam) using huge training data.
Now I have problem implementing the algorithm because of the limitations in the C's datatype.
( Algorithm I am using is given here, http://en.wikipedia.org/wiki/Bayesian_spam_filtering )
PROBLEM STATEMENT: The algorithm involves taking each word in a document and calculating probability of it being spam word. If p1, p2 p3 .... pn are probabilities of word-1, 2, 3 ... n. The probability of doc being spam or not is calculated using

Here, probability value can be very easily around 0.01. So even if I use datatype "double" my calculation will go for a toss. To confirm this I wrote a sample code given below.
#define PROBABILITY_OF_UNLIKELY_SPAM_WORD (0.01)
#define PROBABILITY_OF_MOSTLY_SPAM_WORD (0.99)
int main()
{
int index;
long double numerator = 1.0;
long double denom1 = 1.0, denom2 = 1.0;
long double doc_spam_prob;
/* Simulating FEW unlikely spam words */
for(index = 0; index < 162; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom1 = denom1*(long double)(1 - PROBABILITY_OF_UNLIKELY_SPAM_WORD);
}
/* Simulating lot of mostly definite spam words */
for (index = 0; index < 1000; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom1 = denom1*(long double)(1- PROBABILITY_OF_MOSTLY_SPAM_WORD);
}
doc_spam_prob= (numerator/(denom1+denom2));
return 0;
}
I tried Float, double and even long double datatypes but still same problem.
Hence, say in a 100K words document I am analyzing, if just 162 words are having 1% spam probability and remaining 99838 are conspicuously spam words, then still my app will say it as Not Spam doc because of Precision error (as numerator easily goes to ZERO)!!!.
This is the first time I am hitting such issue. So how exactly should this problem be tackled?