I have an external module, that is returning me some strings. I am not sure how are the strings returned, exactly. I don't really know, how Unicode strings work and why.
The module should return, for example, the Czech word "být", meaning "to be". (If you cannot see the second letter - it should look like this.) If I display the string, returned by the module, with Data Dumper, I see it as b\x{fd}t.
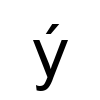{kind=link}
However, if I try to print it with print $s, I got "Wide character in print" warning, and ? instead of ý.
If I try Encode::decode(whatever, $s);, the resulting string cannot be printed anyway (always with the "Wide character" warning, sometimes with mangled characters, sometimes right), no matter what I put in whatever.
If I try Encode::encode("utf-8", $s);, the resulting string CAN be printed without the problems or error message.
If I use use encoding 'utf8';, printing works without any need of encoding/decoding. However, if I use IO::CaptureOutput or Capture::Tiny module, it starts shouting "Wide character" again.
I have a few questions, mostly about what exactly happens. (I tried to read perldocs, but I was not very wise from them)
- Why can't I print the string right after getting it from the module?
- Why can't I print the string, decoded by "decode"? What exactly "decode" did?
- What exactly "encode" did, and why there was no problem in printing it after encoding?
- What exactly
use encodingdo? Why is the default encoding different fromutf-8? - What do I have to do, if I want to print the scalars without any problems, even when I want to use one of the capturing modules?
edit: Some people tell me to use -C or binmode or PERL_UNICODE. That is a great advice. However, somehow, both the capturing modules magically destroy the UTF8-ness of STDOUT. That seems to be more a bug of the modules, but I am not really sure.
edit2: OK, the best solution was to dump the modules and write the "capturing" myself (with much less flexibility).