If you want to search for a single scalar in an array, you can use List::Util's first subroutine. It stops as soon as it knows the answer. I don't expect this to be faster than a hash lookup if you already have the hash, but when you consider creating the hash and having it in memory, it might be more convenient for you to just search the array you already have.
As for the smarts of the smart-match operator, if you want to see how smart it is, test it. :)
There are at least three cases you want to examine. The worst case is that every element you want to find is at the end. The best case is that every element you want to find is at the beginning. The likely case is that the elements you want to find average out to being in the middle.
Now, before I start this benchmark, I expect that if the smart match can short circuit (and it can; its documented in perlsyn), that the best case times will stay the same despite the array size, while the other ones get increasingly worse. If it can't short circuit and has to scan the entire array every time, there should be no difference in the times because every case involves the same amount of work.
Here's a benchmark:
#!perl
use 5.12.2;
use strict;
use warnings;
use Benchmark qw(cmpthese);
my @hits = qw(A B C);
my @base = qw(one two three four five six) x ( $ARGV[0] || 1 );
my @at_end = ( @base, @hits );
my @at_beginning = ( @hits, @base );
my @in_middle = @base;
splice @in_middle, int( @in_middle / 2 ), 0, @hits;
my @random = @base;
foreach my $item ( @hits ) {
my $index = int rand @random;
splice @random, $index, 0, $item;
}
sub count {
my( $hits, $candidates ) = @_;
my $count;
foreach ( @$hits ) { when( $candidates ) { $count++ } }
$count;
}
cmpthese(-5, {
hits_beginning => sub { my $count = count( \@hits, \@at_beginning ) },
hits_end => sub { my $count = count( \@hits, \@at_end ) },
hits_middle => sub { my $count = count( \@hits, \@in_middle ) },
hits_random => sub { my $count = count( \@hits, \@random ) },
control => sub { my $count = count( [], [] ) },
}
);
Here's how the various parts did. Note that this is a logarithmic plot on both axes, so the slopes of the plunging lines aren't as close as they look:
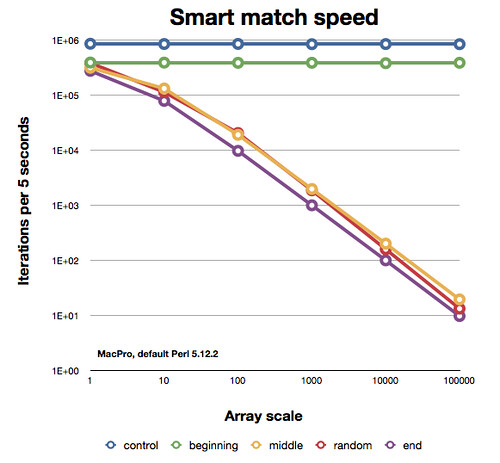
So, it looks like the smart match operator is a bit smart, but that doesn't really help you because you still might have to scan the entire array. You probably don't know ahead of time where you'll find your elements. I expect a hash will perform the same as the best case smart match, even if you have to give up some memory for it.
Okay, so the smart match being smart times two is great, but the real question is "Should I use it?". The alternative is a hash lookup, and it's been bugging me that I haven't considered that case.
As with any benchmark, I start off thinking about what the results might be before I actually test them. I expect that if I already have the hash, looking up a value is going to be lightning fast. That case isn't a problem. I'm more interested in the case where I don't have the hash yet. How quickly can I make the hash and lookup a key? I expect that to perform not so well, but is it still better than the worst case smart match?
Before you see the benchmark, though, remember that there's almost never enough information about which technique you should use just by looking at the numbers. The context of the problem selects the best technique, not the fastest, contextless micro-benchmark. Consider a couple of cases that would select different techniques:
- You have one array you will search repeatedly
- You always get a new array that you only need to search once
- You get very large arrays but have limited memory
Now, keeping those in mind, I add to my previous program:
my %old_hash = map {$_,1} @in_middle;
cmpthese(-5, {
...,
new_hash => sub {
my %h = map {$_,1} @in_middle;
my $count = 0;
foreach ( @hits ) { $count++ if exists $h{$_} }
$count;
},
old_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ if exists $old_hash{$_} }
$count;
},
control_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ }
$count;
},
}
);
Here's the plot. The colors are a bit difficult to distinguish. The lowest line there is the case where you have to create the hash any time you want to search it. That's pretty poor. The highest two (green) lines are the control for the hash (no hash actually there) and the existing hash lookup. This is a log/log plot; those two cases are faster than even the smart match control (which just calls a subroutine).

There are a few other things to note. The line for the "random" case are a bit different. That's understandable because each benchmark (so, once per array scale run) randomly places the hit elements in the candidate array. Some runs put them a bit earlier and some a bit later, but since I only make the @random array once per run of the entire program, they move around a bit. That means that the bumps in the line aren't significant. If I tried all positions and averaged, I expect that "random" line to be the same as the "middle" line.
Now, looking at these results, I'd say that a smart-match is much faster in its worst case than the hash lookup is in its worst case. That makes sense. To create a hash, I have to visit every element of the array and also make the hash, which is a lot of copying. There's no copying with the smart match.
Here's a further case I won't examine though. When does the hash become better than the smart match? That is, when does the overhead of creating the hash spread out enough over repeated searches that the hash is the better choice?