On a Django project, I was hoping to flatten a shallow list with a nested list comprehension, like this:
[image for image in menuitem.image_set.all() for menuitem in list_of_menuitems]
But I get in trouble of the NameError variety there, because the name 'menuitem' is not defined. After googling and looking around on Stack Overflow, I got the desired results with a reduce statement:
reduce(list.__add__, map(lambda x: list(x), [mi.image_set.all() for mi in list_of_menuitems]))
(Note, I need that list(x) call there because x is a Django QuerySet object.)
But the reduce method is fairly unreadable. So my question is:
Is there a simple way to flatten this list with a list comprehension, or failing that, what would you all consider to be the best way to flatten a shallow list like this, balancing performance and readability.
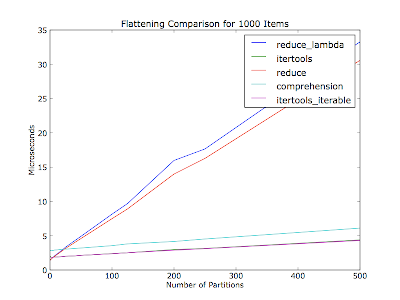
Update: Thanks to everyone who contributed to this question. Here is a summary of what I learned. I'm also making this a community wiki in case others want to add to or correct these observations.
My original reduce statement is redundant and is better written this way:
>>> reduce(list.__add__, (list(mi.image_set.all()) for mi in list_of_menuitems))
This is the correct syntax for a nested list comprehension (Brilliant summary dF!):
>>> [image for mi in list_of_menuitems for image in mi.image_set.all()]
But neither of these methods are as efficient as using itertools.chain:
>>> from itertools import chain
>>> list(chain(*[mi.image_set.all() for mi in h.get_image_menu()]))