Hi,
I have two files A-nodes_to_delete and B-nodes_to_keep. Each file has a many lines with numeric ids.
I want to have the list of numeric ids that are in nodes_to_delete but NOT in nodes_to_keep, e.g. 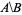 .
.
Doing it within a PostgreSQL database is unreasonably slow. Any neat way to do it in bash using Linux CLI tools?
UPDATE: This would seem to be a Pythonic job, but the files are really, really large. I have solved some similar problems using uniq, sort and some set theory techniques. This was about two or three orders of magnitude faster than the database equivalents.
Adam