Divide and Conquer!
If you do decide to go down the route of doing this 'in-house'. Your design needs to have scalability borne from day 1.
This is one rare case in which the task can be broken down and done in parallel.
If you have 10K documents, even if you built and deployed 10x (scanners + servers + custom app) that would mean each system would only need to handle around 1k documents each.
The challenge would be to make it a cheap and reliable 'turn key solution'.
The application side is probably the easier element, so long as you have a good automated update system designed from the start, you could then simply add hardware as you expand your 'farm/cluster'.
keeping your design modular (i.e. use commodity cheap hardware), will allow you to mix and match hardware/ replace on demand without impacting on daily throughput.
Trial initially to have a turn key solution that can sustain easily 1,000 documents. Then once this works flawlessly scale it up!
Good luck!
Edit 1:
Ok here is a more detailed answer to each specific points you have raised:
What are those systems that are used to scan checks and mail and they
read really messy hand writing really
well?
One such system as used by the mail/post delivery company 'TNT' here in the UK is provided by a Netherlands based company 'Prime Vision' and their HYCR Engine.
I highly suggest you contact them. Handwritten recognition is never going to be very accurate, OCR on printed characters can sometimes achieve 99% accuracy.
has anyone had experience building a database with a bunch of OCR'd
searchable documents? What tools
should I use for my problem?
Not specifically OCR'd documents, but for one of our clients, I build and maintain a very large and complex EDMS which holds a very large variety of document formats. It is searchable in multiple different ways whith complex set of data permission access.
In terms of giving advice, I'd say a few things to bear in mind:
- Keep documents on file and have a link in the database
- Store document directly in Database as BLOB data.
Each approach has its own set of pro's and con's. We opted to go the first route.
In terms of search-ability, once you have the meta data of the actual documents. It is just a matter of creating custom search queries. I built a rank based search, it simply gave a higher ranking to those that matched more of the tokens. Of course you could use of the shelf searching tools (library) such as the Lucene Project.
Can you recommend the best OCR
libraries?
yes:
As a programmer, what would you do to
solve this problem?
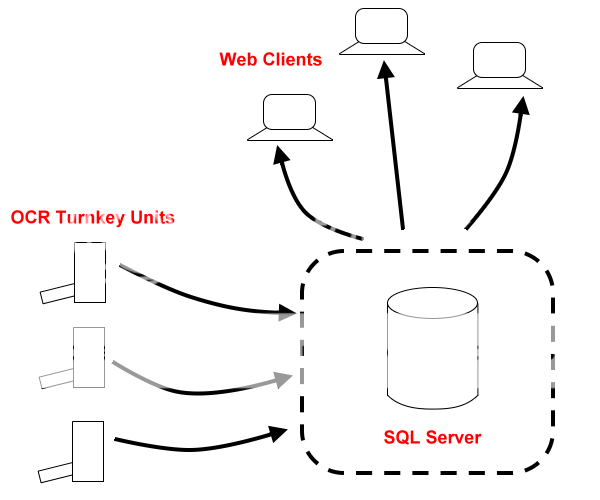
As described above, please see diagram below. The heart of the system will be your Database, you will need to have a presentation front layer to allow clients (could be web application) to search documents in your database. The second part will be the Turnkey based OCR 'servers'.
For these 'OCR Servers' I would simply implement a 'drop folder' (which could be a FTP folder). Your custom application could simply monitor this drop folder (Folder Watcher Class in .NET). Files could be sent directly to this FTP folder.
Your custom OCR application would simply monitor the drop folder and upon receiving a new file, scan it generate the meta data and then move it to a 'Scanned' folder'. The ones that are duplicates or failed to scan can be moved to their own 'Failed Folder'.
The OCR application would then connect to your main Database and do some Inserts or updates (this moves the META DATA to the main database).
In the background you can have your 'Scanned Folder' synchronized with a mirrored folder in your database server (your SQL server as shown in the diagram) (This then physically copies your scanned and OCR'd document to the Main server where the linked records has already been moved.)
Anyway that's how I'd tackle this problem. I've personally implemented one or more of these solutions so I'm confident this would work and be scale-able.
The scale-ability is key here. For this reason you may want to look at alternative database other than the traditional ones.
I would recommend that you at least think about NoSQL type database for this project:
E.g
Un-ashamed Plug:
Of course for £40,000 I'd build and set up the whole solution for you (including hardware) !
:) I'm kidding SO users!
EDIT 2:
Note the mention of META DATA ,by this I mean the same as others have alluded to. The fact that you should retain the original copy of the scanned as an image file, along with the OCR'd meta data (such that it can allow for text searching).
I thought I make this clear, in case it was assumed that it was not part of my solution.