I am trying to automate files download via a webserver. I plan on using wget or curl or python urllib / urllib2.
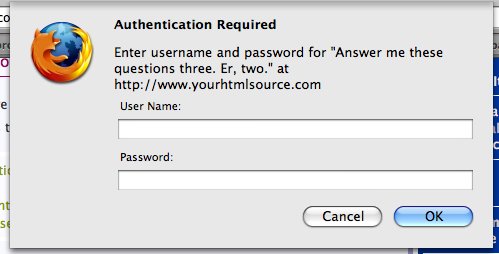
Most solutions use wget and urllib and urllib2. They all talk of HHTP based authentication and cookie based authentication. My problem is I dont know which one is used in the website that stores my data. Here is the interaction with the site:
- Normally I login to site http://www.anysite.com/index.cgi?
- I get a form with a login and password. I type in both and hit return.
- The url stays as http://www.anysite.com/index.cgi? during the entire interaction. But now I have a list of folders and files
- If I click on a folder or file the URL changes to http://shamrockstructures.com/cgi-bin/index.cgi?page=download&file=%2Fhome%2Fjanysite%2Fpublic_html%2Fuser_data%2Fuserareas%2Ffile.tar.bz2
And the browser offers me a chance to save the file
I want to know how to figure out whether the site is using HTTP or cookie based authentication. After which I am assuming I can use cookielib or urllib2 in python to connect to it, get the list of files and folders and recursively download everything while staying connected.
p.S: I have tried the cookie cutter ways to connect via wget and wget --http-user "uname" --http-password "passwd" http://www.anysite.com/index.cgi? , but they only return the web form back to me.
{kind=link}