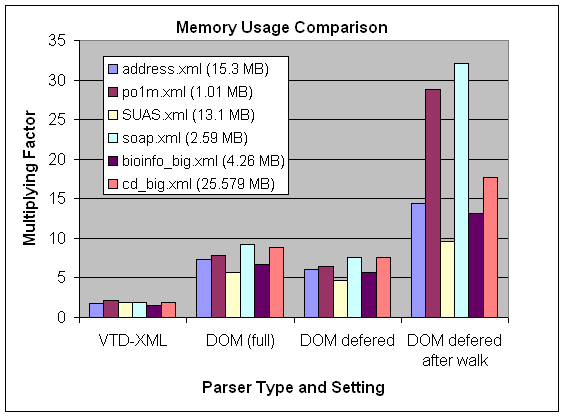
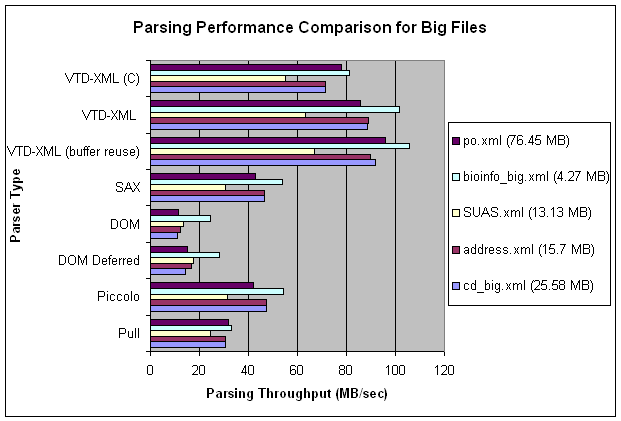
I have a situation where I want to extract some information from some very large but regular XML files (just had to do it with a 500 Mb file), and where XSLT would be perfect.
Unfortunately those XSLT implementations I am aware of (except the most expensive version of Saxon) does not support only having the necessary part of the DOM read in but reads in the whole tree. This cause the computer to swap to death.
The XPath in question is
//m/e[contains(.,'foobar')
so it is essentially just a grep.
Is there an XSLT implementation which can do this? Or an XSLT implementation which given suitable "advice" can do this trick of pruning away the parts in memory which will not be needed again?
I'd prefer a Java implementation but both Windows and Linux are viable native platforms.
EDIT: The input XML looks like:
<log>
<!-- Fri Jun 26 12:09:27 CEST 2009 -->
<e h='12:09:27,284' l='org.apache.catalina.session.ManagerBase' z='1246010967284' t='ContainerBackgroundProcessor[StandardEngine[Catalina]]' v='10000'>
<m>Registering Catalina:type=Manager,path=/axsWHSweb-20090626,host=localhost</m></e>
<e h='12:09:27,284' l='org.apache.catalina.session.ManagerBase' z='1246010967284' t='ContainerBackgroundProcessor[StandardEngine[Catalina]]' v='10000'>
<m>Force random number initialization starting</m></e>
<e h='12:09:27,284' l='org.apache.catalina.session.ManagerBase' z='1246010967284' t='ContainerBackgroundProcessor[StandardEngine[Catalina]]' v='10000'>
<m>Getting message digest component for algorithm MD5</m></e>
<e h='12:09:27,284' l='org.apache.catalina.session.ManagerBase' z='1246010967284' t='ContainerBackgroundProcessor[StandardEngine[Catalina]]' v='10000'>
<m>Completed getting message digest component</m></e>
<e h='12:09:27,284' l='org.apache.catalina.session.ManagerBase' z='1246010967284' t='ContainerBackgroundProcessor[StandardEngine[Catalina]]' v='10000'>
<m>getDigest() 0</m></e>
......
</log>
Essentialy I want to select some m-nodes (and I know the XPath is wrong for that, it was just a quick hack), but maintain the XML layout.
EDIT: It appears that STX may be what I am looking for (I can live with another transformation language), and that Joost is an implementation hereof. Any experiences?
EDIT: I found that Saxon 6.5.4 with -Xmx1500m could load my XML, so this allowed me to use my XPaths right now. This is just a lucky stroke so I'd still like to solve this generically - this means scriptable which in turn means no handcrafted Java filtering first.
EDIT: Oh, by the way. This is a log file very similar to what is generated by the log4j XMLLayout. The reason for XML is to be able to do exactly this, namely do queries on the log. This is the initial try, hence the simple question. Later I'd like to be able to ask more complex questions - therefore I'd like the query language to be able to handle the input file.