Here is the setup. No assumptions for the values I am using.
n=2; % dimension of vectors x and (square) matrix P
r=2; % number of x vectors and P matrices
x1 = [3;5]
x2 = [9;6]
x = cat(2,x1,x2)
P1 = [6,11;15,-1]
P2 = [2,21;-2,3]
P(:,1)=P1(:)
P(:,2)=P2(:)
modePr = [-.4;16]
TransPr=[5.9,0.1;20.2,-4.8]
pred_modePr = TransPr'*modePr
MixPr = TransPr.*(modePr*(pred_modePr.^(-1))')
x0 = x*MixPr
Then it was time to apply the following formula to get myP
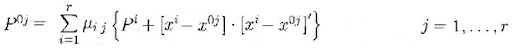
, where μij is MixPr. I used this code to get it:
myP=zeros(n*n,r);
Ptables(:,:,1)=P1;
Ptables(:,:,2)=P2;
for j=1:r
for i = 1:r;
temp = MixPr(i,j)*(Ptables(:,:,i) + ...
(x(:,i)-x0(:,j))*(x(:,i)-x0(:,j))');
myP(:,j)= myP(:,j) + temp(:);
end
end
Some brilliant guy proposed this formula as another way to produce myP
for j=1:r
xk1=x(:,j); PP=xk1*xk1'; PP0(:,j)=PP(:);
xk1=x0(:,j); PP=xk1*xk1'; PP1(:,j)=PP(:);
end
myP = (P+PP0)*MixPr-PP1
I tried to formulate the equality between the two methods and seems to be this one. To make things easier, I skipped the summation of matrix P in both methods .
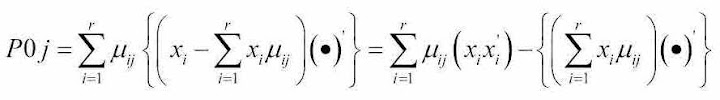
where the first part denotes the formula that I used, and the second comes from his code snippet. Do you think this is an obvious equality? If yes, ignore all the above and just try to explain why. I could only start from the LHS, and after some algebra I think I proved it equals to the RHS. However I can't see how did he (or she) think of it in the first place.