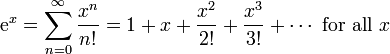Since it's not possible to calculate every digit of 'e', you're going to have to pick a stopping point.
double precision: 16 decimal digits
For practical applications, "the 64-bit double precision floating point value that is as close as possible to the true value of 'e' -- approximately 16 decimal digits" is more than adequate.
As KennyTM said, that value has already been pre-calculated for you in the math library.
If you want to calculate it yourself, as Hans Passant pointed out, factorial already grows very fast.
The first 22 terms in the series is already overkill for calculating to that precision -- adding further terms from the series won't change the result if it's stored in a 64 bit double-precision floating point variable.
I think it will take you longer to blink than for your computer to do 22 divides. So I don't see any reason to optimize this further.
thousands, millions, or billions of decimal digits
As Matthieu M. pointed out, this value has already been calculated, and you can download it from Yee's web site.
If you want to calculate it yourself, that many digits won't fit in a standard double-precision floating-point number.
You need a "bignum" library.
As always, you can either use one of the many free bignum libraries already available, or re-invent the wheel by building your own yet another bignum library with its own special quirks.
The result -- a long file of digits -- is not terribly useful, but programs to calculate it are sometimes used as benchmarks to test the performance and accuracy of "bignum" library software, and as stress tests to check the stability and cooling capacity of new machine hardware.
One page very briefly describes the algorithms Yee uses to calculate mathematical constants.
The Wikipedia "binary splitting" article goes into much more detail.
I think the part you are looking for is the number representation:
instead of internally storing all numbers as a long series of digits before and after the decimal point (or a binary point),
Yee stores each term and each partial sum as a rational number -- as two integers, each of which is a long series of digits.
For example, say one of the worker CPUs was assigned the partial sum,
... 1/4! + 1/5! + 1/6! + ... .
Instead of doing the division first for each term, and then adding, and then returning a single million-digit fixed-point result to the manager CPU:
// extended to a million digits
1/24 + 1/120 + 1/720 => 0.0416666 + 0.0083333 + 0.00138888
that CPU can add all the terms in the series together first with rational arithmetic, and return the rational result to the manager CPU: two integers of perhaps a few hundred digits each:
// faster
1/24 + 1/120 + 1/720 => 1/24 + 840/86400 => 106560/2073600
After thousands of terms have been added together in this way, the manager CPU does the one and only division at the very end to get the decimal digits after the decimal point.
Remember to avoid PrematureOptimization, and
always ProfileBeforeOptimizing.