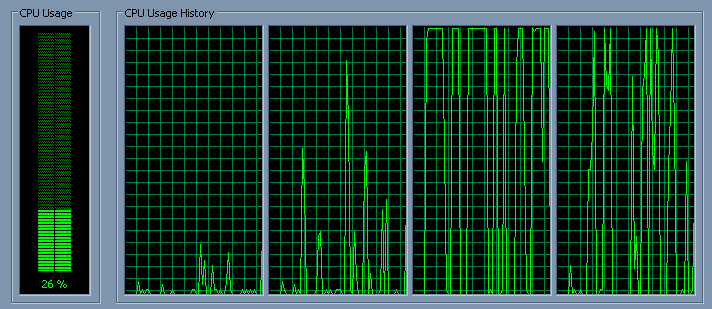
Once I noticed that Windows doesn't keep computation-intensive threads on a specific core - it keeps switching cores instead. So I speculated that the job would be done faster, if the thread would keep access to the same data caches. And really, I was able to observe a stable ~1% speed improvement after setting the thread's affinity mask to a single core (in a ppmd (de)compression thread). But then I tried to build a simple demo for this effect, and more or less failed - that is, it works as expected on my system (Q9450):
buflog=21 bufsize=2097152 (cache flush) first run = 6.938s time with default affinity = 6.782s time with first core only = 6.578s speed gain is 3.01%
but people I asked weren't exactly able to reproduce the effect. Any suggestions?
#include <stdio.h>
#include <windows.h>
int buflog=21, bufsize, bufmask;
char* a;
char* b;
volatile int r = 0;
__declspec(noinline)
int benchmark( char* a ) {
int t0 = GetTickCount();
int i,h=1,s=0;
for( i=0; i<1000000000; i++ ) {
h = h*200002979 + 1;
s += ((int&)a[h&bufmask]) + ((int&)a[h&(bufmask>>2)]) + ((int&)a[h&(bufmask>>4)]);
} r = s;
t0 = GetTickCount() - t0;
return t0;
}
DWORD WINAPI loadcore( LPVOID ) {
SetThreadAffinityMask( GetCurrentThread(), 2 );
while(1) benchmark(b);
}
int main( int argc, char** argv ) {
if( (argc>1) && (atoi(argv[1])>16) ) buflog=atoi(argv[1]);
bufsize=1<<buflog; bufmask=bufsize-1;
a = new char[bufsize+4];
b = new char[bufsize+4];
printf( "buflog=%i bufsize=%i\n", buflog, bufsize );
CreateThread( 0, 0, &loadcore, 0, 0, 0 );
printf( "(cache flush) first run = %.3fs\n", float(benchmark(a))/1000 );
float t1 = benchmark(a); t1/=1000;
printf( "time with default affinity = %.3fs\n", t1 );
SetThreadAffinityMask( GetCurrentThread(), 1 );
float t2 = benchmark(a); t2/=1000;
printf( "time with first core only = %.3fs\n", t2 );
printf( "speed gain is %4.2f%%\n", (t1-t2)*100/t1 );
return 0;
}
P.S. I can post a link to compiled version if anybody needs that.