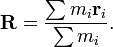OK. I get it now. You have a vast number of discrete particles to work with. With emphasis on the big number.
Well, why didn't you say?
You can't do it exactly (i.e. without approximation) any faster than iterating though all the points. At least not without providing more relevant information.
Adam's sampling suggestion is a good way to obtain an approximation if you have random access to the data.
An alternative that won't be faster for a single operation, but might be useful if you are going to have to recalculate often is to reduce the working set to a smaller group of heavier points. Something like this:
- Divide space into a grid of
N_x * N_y * N_z cells of sizes (l_x,l_y,L_z).
- Compute the total mass and location of the center of mass for all the points in each cell.
- Discard any cells with no points contained, and use the results as the new working set.
For this to represent an improvement, you'll want to have an average of 10 or more original points per cell, but not so many that the introduced grandularity washes out the signal you are looking for.
How best to do step 2 depends on how the original data is organized and on how much room you have in memory to store intermediate results. With lots of memory available:
- Prepare and initialize to zero four (N_x,N_y,N_z) arrays called
M, Rx, Ry, and Rz (or one scalar array M and one vector array R, that depends on your implementation language)
- Walk the main list on time, incrementing the values in the appropriate cell for each mass
- Walk the intermediate arrays to figure the collected masses and locations.
With relatively little memory but lots of time available for pre-calculation you would walk the main list once for every cell (but if you have that kind of time you probable can just do this straight).