If I have a straight line that mesures from 0 to 1, then I have colorA(255,0,0) at 0 on the line, then at 0.3 I have colorB(20,160,0) then at 1 on the line I have colorC(0,0,0). How could I find the color at 0.7?
Thanks
If I have a straight line that mesures from 0 to 1, then I have colorA(255,0,0) at 0 on the line, then at 0.3 I have colorB(20,160,0) then at 1 on the line I have colorC(0,0,0). How could I find the color at 0.7?
Thanks
Here is some pseudocode:
percentage = (x - min) / (max - min)
percentage = (.7 - .3) / (1 - .3)
colorAtPoint = colorB + percentage*(colorC - colorB)
colorAtPoint = (20+(percentage*-20),
160+(percentage*-160),
(0+(percentage*0))
Try to convert this to another color-representation, e.g. HSV (see http://en.wikipedia.org/wiki/HSL_and_HSV).
? means that it actually doesn't matter (since color C is simply black).
Now also convert color B to an HSV (can't do this out of my head, sorry), then choose nice values for the Hue and Saturation of color C so that the Hue, Value and Saturation are on one line in the HSV space. Then deduct the color at 0.7 from it.
EDIT: Using the RGB-HSV calculator at http://www.csgnetwork.com/csgcolorsel4.html I calculated the following:
Now we calculate the H and V of color C like this:
This gives us for the color at 0.7:
Unfortunately, this doesn't fit completely for the Saturation, but if you interpolate this way, you will get something that's very close to what you want.
it looks like you are trying to interpolate in the wrong color space. First convert to HSV, then your colors become
RGB -> HSV
255,0,0 -> 0, 255,255
20,160,0 -> 80,255,160
0,0,0 -> 0,255,0
so its still confusing but at least we can see that the V value is interpolating to zero, the H value is confusing, but after realizing that HSV is modeled as a cylinder, we can see that it is really just interpolating from 0 to 256 mod 256, so it just goes back to zero.
so your equation would be (in HSV)
nH = frac*256 mod 256
nS = 255
nV = (1-frac)*255
So if you substitute 0.7 for frac you will get the right calculation in HSV coordinates, if you need to go back to RGB you should see if your libraries provide such a feature (i know java's Color class supports this), but if not you can just grab the code from here. it shows how to do color space conversions in C.
Good luck
In the abstract, you're asking for the value of f(0.7) given that f(0.0) = (255, 0, 0), f(0.3) = (20, 160, 0), and f(1.0) = (0, 0, 0). As stated, this isn't well-defined as f could be any of an infinite number of functions.
Some possible choices for f are:
But the particular choice of how f should be defined should depend on what you're doing, or how the color stops are defined for your application.
The correct way to interpolate RGB is to correct for gamma first, making the color components linear, perform an interpolation, and then convert back. Otherwise you will get errors due to the values being nonlinear. See http://www.4p8.com/eric.brasseur/gamma.html for more information (although the article is about scaling, scaling is usually done by interpolating pixel values).
If you have sRGB values, you can convert between linear and nonlinear using the formulas here: http://en.wikipedia.org/wiki/SRGB (use the Csrgb and Clinear formulas)
On the other hand, the errors are not huge, so it depends on your application if they matter.
For the interpolation itself, simple linear interpolation should suffice (as others here have noted). See http://en.wikipedia.org/wiki/Linear_interpolation for the specifics.
[Elaborating on my comments to Patrick -- it all got a bit out of hand!]
This is really an interesting question, and one of the reasons it's interesting is that there is no "right" answer. Colour representation and data interpolation can both be done in many different ways. You need to tailor your approach appropriately for your problem domain. Since we haven't been given much a priori information about that domain, we can only explore some of the possibilities.
The business of colours muddies the water somewhat, so let's put that aside temporarily and think first about interpolation of simple scalars.
Let's say we have some data points like this:

What we want to find is what the y value on this graph will be at points along the x axis other than the ones for which we have known values. That is, we're looking for a function
y = f(x)
that passes through these points.
Clearly, there are many different ways we could choose to join the dots. We might just link them up with straight line segments. Or we might want a smooth curve, and that curve could be simple or arbitrarily complicated:
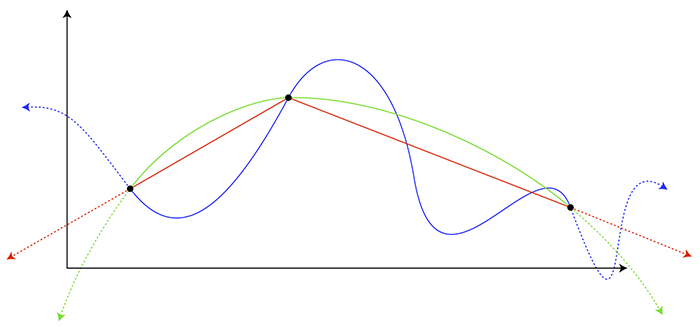
Here, it's easy to understand where the red lines come from -- we're just drawing straight lines from one known point to the next. The green line also looks sort of reasonable, though we're adding some assumptions about how the curve should behave. The blue line, on the other hand, would be hard to justify on the basis of the data points alone, but there might be circumstances where we have reasons to model the system using such a shape -- as we'll see a bit later.
Note also the dotted lines heading off the sides of each curve. These are going beyond the known points, which is called extrapolation rather than interpolation. This is often a bit more questionable than interpolation. At least when you're going from one known point to another you have some evidence you're headed the right way. Whereas the further you get from the known points, the more likely it is you'll stray from the path. But still, it's a useful technique and it may well make sense.
OK, so the picture is pretty and all, but how do we generate these lines?
We need to find an f(x) that will give us the desired y. There are many different functions we could use depending on the circumstances, but by far the most common is to use a polynomial function, ie:
f(x) = a0 + a1 * x + a2 * x * x + a3 * x * x * x + ....
Now, given N distinct data points, it is always possible to find a perfectly-fitting curve using a polynomial of degree N-1 -- a straight line for two points, a parabola for three, a cubic for four, etc -- but unless the data are unusually well-behaved the curve tends to go haywire as the degree goes up. So unless there is a good reason to believe that the data's behaviour is well modelled by higher-degree polynomials, it's usual instead to interpolate the data piecewise, fitting a different curve segment between each successive pair of points.
Typically, each segment is modelled as a polynomial of degree 1 or 3. The former is just a straight line, and is used because it is really easy and requires no information than the two data points themselves. The latter is a cubic spline and is used because it is the simplest polynomial that will gives you a smooth transition across each point. However, calculating it is a bit more complex and requires two extra pieces of information for each segment (exactly what those pieces are depends on the particular spline form you use).
Linear interpolation is easy enough to go in one line of code. If our first data point is (x1, y1) and our second is (x2, y2), then the linearly-interpolated y at any intermediate x is:
y = y1 + (x - x1) * (y2 - y1) / (x2 - x1)
(Variations on this appear in some of the other answers.)
Cubic splines are a bit too involved to go into here, but Google should turn up some decent references. They are arguably overkill in this case anyway, since you only have three points.
With all that under our belts, let's take a look at the problem as described:
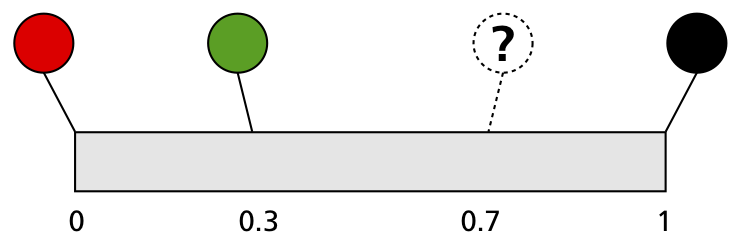
We have a line (shown here in grey) whose colour is known only at three points, and we're asked to calculate what the colour will be at some other point. Since we don't have any knowledge of how the colorus are distributed, we have to make some assumptions.
One key assumption is that colour changes along the line will be continuous, at least to some approximation. Clearly, if the line really looked like this:

then all that earlier stuff about interpolation would go out the window. We'd have no basis for deciding what colour any part should be and should just give up and go home. Let's assume that's not the case and we have something to interpolate.
The known colours are specified as RGB. In this representation, each channel is a separate scalar value and we can choose to treat it as completely independent of the others. So, one perfectly reasonable approach would be to do a piecewise linear interpolation of each channel and then recombine the results.
Doing so gives us something like this:

This is fine as far as it goes, but there are aspects of the result we might not like. One is that the transition from red to green passes through a pretty murky grey-brown. Another is that the green peak at 0.3 is a bit sharp.
It's important to note that, in the absence of a more comprehensive specification, these are really just aesthetic concerns. Our technique is perfectly sound, but it isn't giving quite the sort of results we might want. This sort of thing depends on our specific problem domain, and ultimately it's all a matter of choice.
Since we have just three data points -- and since Hans Passant suggested it -- perhaps we could instead try fitting a parabola to model the whole curve on each channel? It's true we don't have any reason to think that this is a good model, but it doesn't hurt to try:

The differences between this gradient and the last one are instructive. The quadratic has smoothed things out, but has also overshot dramatically. Remember, the green channel both starts and ends at 0. A parabola is symmetrical, so its maximum has to be in the middle. The only way it can fit a green rise towards 0.3 is by continuing to rise all the way to 0.5. (There's a similar effect in the red channel, but it's less obvious because in this case it's an undershoot and the value is clamped to 0.)
Do we have any evidence that this sort of shape is really there in our colour line? Nope: we've explicitly introduced it via our choice of model. That doesn't invalidate it -- we might have good reasons for wanting it to work that way -- once again it's a matter of choice.
So far we've stuck to the original RGB colour space, but as various people rushed to point out this can be less than ideal for interpolation: colour and intensity are bound together in RGB, so interpolating between two different full-intensity colours typically takes you through some drab low-intensity intermediate.
In HSV representation, colour and intensity are on separate dimensions, so we don't get that problem. Why not convert and do the interpolation in that space instead?
This immediately gives rise to a difficulty -- or at any rate, another decision. The mapping between HSV and RGB is not bijective; in particular, black, which happens to be one of our three data points, is a single point in RGB space but occupies a whole plane in HSV. We cannot interpolate between a point and a plane, so we need to pick one specific HSV black point to go to.
This is the basis of Patrick's ingenious solution, in which H and S are specifically chosen to make the whole colour gradient linear. The result looks something like this:

This looks a lot prettier and more colourful than the previous attempts, but there are a few things we might quibble with.
One important issue is that in the case of V, where we still have definite data at all three points, those data are not actually linear, and so the linear fit is only an approximation. What this means is that the value we see here at 0.3 is not quite what it should be.
Another, to my mind bigger, quibble: where is all that blue coming from? All three of our known RGB data points have B=0. It seems a bit strange to suddenly introduce a whole bunch of blue for which we seem to have no evidence at all. Check out this graph of the RGB components in Patrick's HSV interpolation:
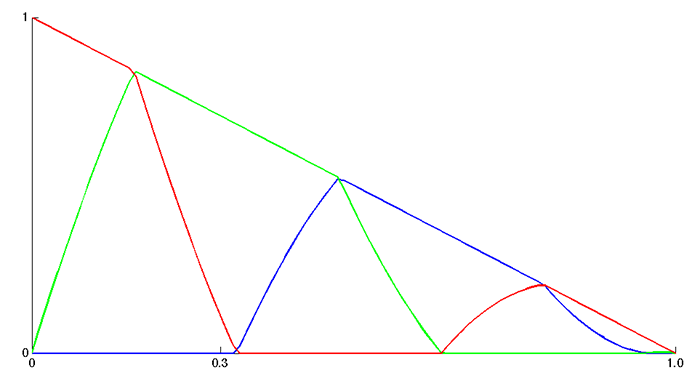
The reason for the blue is, of course, that in switching colour spaces we have specifically selected a model where if you keep on going from green you inevitably get to blue. At the same time, we have had to discard one of our hue data points, and have chosen to fill it in by linear extrapolation from the other two, which means we do just keep on going, from green to blue to over the hills and far away.
Once again, this isn't invalid, and we might have a good reason for doing it this way. But to my mind it's a little but more out there than the previous piecewise-linear example, because of that extrapolation.
So is this the only way to do it in HSV? Of course not. There are always more choices.
For example, instead of choosing H and S values at 1.0 to maximise linearity, how about we instead choose them to minimise change in a piecewise linear interpolation? As it happens, for S the two strategies coincide: it is 100 at both points, so we make it 100 at the end too. The two segments are collinear. For H, though, we just keep it the same over the second segment. This gives a result like this:

This is not quite as cute as the previous one, but it seems slightly more plausible to me. Once again, though, that's largely an aesthetic judgement. That doesn't make this the "right" answer, anymore than it makes Patrick's or any of the others "wrong". As I said way back at the start, there is no "right" answer. It's all a matter of making choices according to your needs in a particular problem -- and being aware that you have made those choices and how they affect your outcome.