Several of the resources I've gone to on the internet have disagree on how set associative caching works.
For example hardware secrets seem to believe it works like this:
Then the main RAM memory is divided in the same number of blocks available in the memory cache. Keeping the 512 KB 4-way set associative example, the main RAM would be divided into 2,048 blocks, the same number of blocks available inside the memory cache. Each memory block is linked to a set of lines inside the cache, just like in the direct mapped cache.
http://www.hardwaresecrets.com/printpage/481/8
They seem to be saying that each cache block(4 cache lines) maps to a particular block of contiguous RAM. They are saying non-contiguous blocks of system memory(RAM) can't map to the same cache block.
This is there picture of how hardwaresecrets thinks it works http://www.hardwaresecrets.com/fullimage.php?image=7864
Contrast that with wikipedia's picture of set associative cache http://upload.wikimedia.org/wikipedia/commons/9/93/Cache%2Cassociative-fill-both.png.
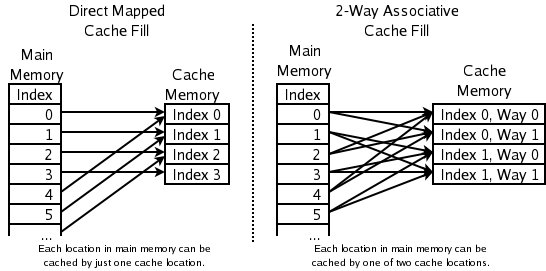{kind=link}
Brown disagrees with hardware secrets
Consider what might happen if each cache line had two sets of fields: two valid bits, two dirty bits, two tag fields, and two data fields. One set of fields could cache data for one area of main memory, and the other for another area which happens to map to the same cache line.
http://www.spsu.edu/cs/faculty/bbrown/web_lectures/cache/
That is, non-contiguous blocks of system memory can map to the same cache block.
How are the relationships between non-contiguous blocks on system memory and cache blocks created. I read somewhere that these relationships are based on cache strides, but I can't find any information on cache strides other than that they exist.
Who is right? If striding is actually used, how does striding work and do I have the correct technical name? How do I find the stride for a particular system? is it based on the paging system? Can someone point me to a url that explains N-way set associative cache in great detail?
also see: http://www.cs.umd.edu/class/sum2003/cmsc311/Notes/Memory/set.html