Hey All,
So I think I'm going to get buried for asking such a trivial question but I'm a little confused about something.
I have implemented quicksort in Java and C and I was doing some basic comparissons. The graph came out as two straight lines, with the C being 4ms faster than the Java counterpart over 100,000 random integers.
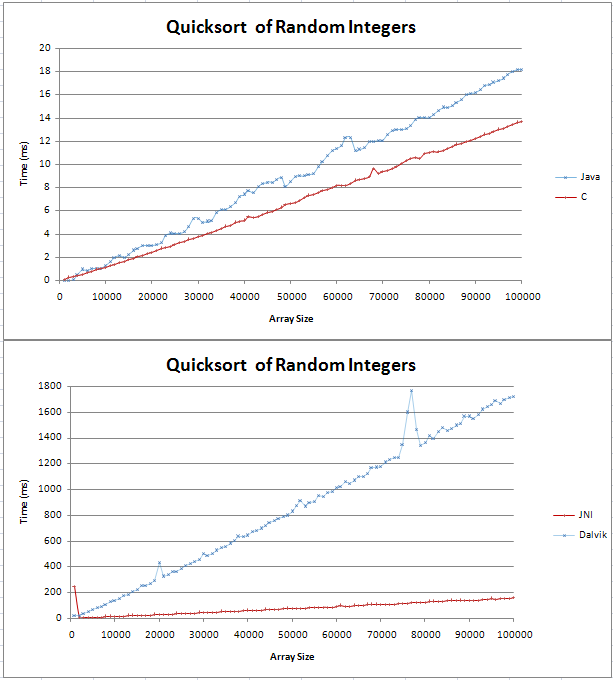
The code for my tests can be found here;
I wasn't sure what an (n log n) line would look like but I didn't think it would be straight. I just wanted to check that this is the expected result and that I shouldn't try to find an error in my code.
I stuck the formula into excel and for base 10 it seems to be a straight line with a kink at the start. Is this because the difference between log(n) and log(n+1) increases linearly?
Thanks,
Gav